1. INTRODUCTION
Typically, computer vision applications are merely based on optical RGB representations, with dependency on appearance information, which implies several limitations, such as: segmentation of similar color objects, detection in dynamic scenarios, sensibility to illumination changes, or even strong variability recognition for different perspectives. The current RGB-D (Kinect) devices have allowed to introduce new information to better represent objects of interest from depth scenes. This new multimodal analysis has allowed addressing new perspectives for classical vision problems, such as: 3D reconstruction, human tracking, human interaction, among many others. Also this kind of analysis helps with typical problems of illumination changes and perspective. The computation of RGB-D primitives results useful to understand complex scenarios by capturing and characterizing more accurately the different objects of interest in a particular problem. Nevertheless, the depth sensors are limited in resolution and some little environment perturbations lead to noisy measurements. Additionally, the use of depth information is complex because of the nonlinear correlation between depth and optical information, for instance scale differences and strong dependency on intrinsic video device parameters. Even worst, the computation of motion primitives implies the association of temporal RGB frames along the sequences, which increase the complexity of computational approaches.
In the state-of-the-art has been proposed several strategies to recover low level features and to develop image descriptors from RGB-D information. For instance, Blum et. al. [1] introduces a RGB-D clustering algorithm that recovers regional patterns from SIFT points. Such approach is however dependent of features in cluster, and the SIFT points discard depth information. In [2] it was analyzed the representation of scenes by computing interest points in appearance and depth information, independently. Interestingly, in that work it is reported that a better characterization for recognition is achieved only using appearance features. Such evaluation can be justified because richness in RBG space while depth information has coarse levels of representation. Nevertheless, in the reported work authors suggest the use of appearance points but complemented with depth information in a low level scale by using average measures around points. In this sense, SIFT and HOG descriptors were extended in RGB-D sequences, achieving an improvement of 10% in a classical object recognition task [3].
Regarding motion analysis, seminal works have analyzed temporal changes of silhouettes estimated from depth channels [4]. These approaches remove dependencies of appearance and result efficient in time computation. However, a main problem in such global representation is the dependency of perspective and the restrictions w.r.t occlusion. Also, a typical motion characterization is carried out from the computation of the appearance’s velocity field between consecutive frames to recover the displacement of an object of interest characterized from its appearance. From a RGB-D perspective, several strategies has been proposed to recover scene fields among consecutive frames, achieving a 3D local displacement characterization [5,6,7]. Such scene flows give important kinematics primitives but they are however, prone to errors because of the low resolution depth maps that limit the correlation with optical information along the sequence [8]. In [9] was proposed a scene flow approach that firstly computes a classical dense optical flow and then add depth information to recover 3D velocity information. This approach is nevertheless limited to include only brightness restriction which interferes with the field correspondence in depth. In [10] was proposed a simultaneous localization and mapping (SLAM) strategy that generates a 3D point cloud at each time. Hence, an environment measurement model (EMM) computes a set of rigid transformation between consecutive clouds to obtain a graph of correspondence to estimate a scene flow. This approach was extended to compute trajectories to track robots in controlled environments. However, the graph representation is computationally complex and the cloud correspondence can fail when abrupt motions are present. Herbest et. al. [7] also proposed a scene flow strategy but using non-linear operators to model color and depth. This approach is able to recover dense flows even in uniform scenarios. A main drawback of scene flow characterization is the description only between consecutive pairs of frames, limiting the kinematics description of objects to first order primitives.
This work introduces a novel strategy that computes 3D+t long trajectories as local kinematics primitives of RGB-D sequences. These long trajectories allow recovering coherent local motion information along the sequences that can be used to analyze object in the scene. Firstly, a scene flow is computed along the video to obtain sequential velocity fields. Hence, a local point tracking is defined over a grid of pixels to follow the corresponding velocity vectors. Several trajectories are removed because of abrupt motions among consecutive frames or given the static performance. Each of the recovered trajectories was characterized from local kinematics metrics, such as average and variation of velocities, curvature and torsion. This kinematics is a word to represent a set of object motions recorded in videos. The motion words are coded into a bag of words scheme to validate the performance of obtained trajectories. Validation of proposed trajectories was carried out into a scheme of recognition of gestures recorded in RGB-D sequences.
2. MATERIALS AND METHODS
In this work is presented a computational strategy to recover 3D+t trajectories able to locally characterize RGB-D sequences. The proposed approach starts by recovering 3D velocity fields between consecutive frames as an initial scene flow characterization (subsection 2.1). These velocity fields help to track uniform points along the sequence that constitutes long term trajectories (subsection 2.2). A set of differential kinematics are computed along each trajectory to obtain a video representation (subsection 2.3). Finally, a bag-of-kinematics words is built to obtain a final descriptor of the proposed trajectories in the problem of gesture representation (subsection 2.4). Next subsections describe each of the steps considered in the proposed strategy.
2.1 RGB-D scene flow characterization
The computation of motion fields, between consecutive frames, from optical flow strategies is one of the most relevant primitives in computer vision to represent objects of interest. These strategies are relatively independent to appearance, robust to some changes of interest and can recover additional features to complement a recognition analysis. Classical optical flows approaches include the Lucas and Kanade [11] that solve a linear problem to find edge motion vectors in the scene. On the other hand, Horn and Schunck [12] introduces global restriction and variational approaches to recover dense motion field’s estimations. These two main works have given rise to novel applications and new strategies based on motion quantification [9], [13], and [7].
Taking advantage of RGB-D sequences, scene flow characterization strategies allow recovering 3D local velocities as a set of three-dimensional displacement vectors in consecutive frames. In this work it was implemented a variational strategy that includes local and global restrictions to preserve motion discontinuities and to recover scene flow estimations following the model proposed by Quiroga et.al. in [9]. This 3D flow strategy models rotational and translational motions by using local and global restrictions of 3d scene points. Such restriction allows a better estimation of 3D rotation and non-rigid motions.
In
general
a 3D motion could be measured as the difference between two
consecutive
cloud points, represented in real world coordinates as: ![]() .
This motion can be approximated as a scene flow
.
This motion can be approximated as a scene flow ![]() taking into
account the
taking into
account the ![]() projection
over the brightness images,
together with corresponding depth values
projection
over the brightness images,
together with corresponding depth values ![]() . Then a first
motion consistency is defined
from both: brightness
. Then a first
motion consistency is defined
from both: brightness ![]() and depth
consistency
and depth
consistency ![]() , measured over a
local region
, measured over a
local region ![]() . For doing
so, the brightness consistency is
measured among consecutive frames as:
. For doing
so, the brightness consistency is
measured among consecutive frames as: ![]() , while the depth
consistency is expressed as:
, while the depth
consistency is expressed as: ![]() . Hence a general 3D
flow motion consistency is
defined in whole space x as:
. Hence a general 3D
flow motion consistency is
defined in whole space x as:
|
|
(1) |
where
![]() is
a
Charbonnier penalty and
is
a
Charbonnier penalty and ![]() is
a predefined weight
for both considered consistencies. Additionally, a second
restriction was
considered to capture large coherent 3D displacements. This
displacement allows
recovering coherent abrupt motion that represents the
kinematics signature of some
objects. In such cases, a set of sparse SIFT points
is
a predefined weight
for both considered consistencies. Additionally, a second
restriction was
considered to capture large coherent 3D displacements. This
displacement allows
recovering coherent abrupt motion that represents the
kinematics signature of some
objects. In such cases, a set of sparse SIFT points ![]() are
computed from
optical images, from which are measured a 3D motion
consistency w.r.t to couple
points in the next frame
are
computed from
optical images, from which are measured a 3D motion
consistency w.r.t to couple
points in the next frame ![]() .
The minimization
matching term is then defined, as:
.
The minimization
matching term is then defined, as:
|
|
(2) |
with
![]() in
regions around of
an SIFT interest point. A third restriction
in
regions around of
an SIFT interest point. A third restriction ![]() is
defined over the
captured field and acts as local regularization term to
favor locally rigid
motions and preserve motion discontinuities in depth. This
restriction is
minimized w.r.t the gradients of computed field in each of
their axis, and
weighted by a function
is
defined over the
captured field and acts as local regularization term to
favor locally rigid
motions and preserve motion discontinuities in depth. This
restriction is
minimized w.r.t the gradients of computed field in each of
their axis, and
weighted by a function ![]() that
helps to
regularize the field w.r.t the computed depth map. This flow
rule minimization
is expressed as:
that
helps to
regularize the field w.r.t the computed depth map. This flow
rule minimization
is expressed as:
|
|
(3) |
This approach uses a regularized variational function to
obtain a total dense
scene field, while preserving motion discontinuities. The
scene flow is finally
obtained as the sum of three restriction defined above. In
Fig. 1 is
illustrated a typical computation of scene flow for a couple
of frames. It is
shown a gray-map representation of the ![]() components
separately.
components
separately.
Despite of 3D motions have demonstrated to be useful to describe dynamic scenes, these primitives are limited to measuring only each consecutive pair of frames. From RGB-D information, the implemented strategy achieves a dense 3D field representation of the scene.
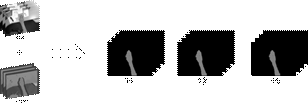 Fig.
1. Scene flow. The
3D motion between a pair of consecutive RGB-D images is
obtained from the scene
flow information. Please visit the site: (to be announced)
to observe the image
in color.
Fig.
1. Scene flow. The
3D motion between a pair of consecutive RGB-D images is
obtained from the scene
flow information. Please visit the site: (to be announced)
to observe the image
in color.
Source: The authors.
2.2 Computing long motion trajectories
Taking advantage of dense optical flow description, in the literature has been proposed new kinematics models that search to extend motion information in more than two frames. It consists of local motion trajectories that represent local primitives that follow interest points along the sequences, describing kinematics information in relatively large intervals of time [14,15]. For instance the KLT-Tracker uses an extension of pyramidal Lukas-Kanade [16] to follow relevant motion vectors, obtaining coherent motion trajectories of coherent edges along the sequence. Such representation is nevertheless dispersed and only produces few trajectories to represent the motion of an object. Also, Sun et. al. [14], proposed the capture of salient interest SIFT points by carrying out a coherent matching along the sequence. This approach extends the performance of SIFT points, being invariant to scale and rotation but only representing few points along the scene which can limit a statistical representation of the objects. On the other hand, Wang et. al. proposed a dense trajectories representation by following independent fields of motion along the videos. Such representation has been proofed to be useful in action representation tasks for classical RGB sequences.
Inspired
in
such dense trajectories, in this work is proposed an
extension of dense
trajectories computed in RGB-D spaces, which allows
capturing ![]() long
trajectories.
These proposed trajectories can enrich the kinematics
description of the object
by computing higher-order motion representations. Also, the
trajectories can be
used as bases to recover local RGB-D descriptors. For doing
so, the proposed
strategy starts by computing a point cloud from the RGB-D
sequences at each
time. This cloud point assumes a pre-processing and
calibration of RGB and
depth images. Then, a dense sampling is carried out from the
cloud point
long
trajectories.
These proposed trajectories can enrich the kinematics
description of the object
by computing higher-order motion representations. Also, the
trajectories can be
used as bases to recover local RGB-D descriptors. For doing
so, the proposed
strategy starts by computing a point cloud from the RGB-D
sequences at each
time. This cloud point assumes a pre-processing and
calibration of RGB and
depth images. Then, a dense sampling is carried out from the
cloud point ![]() taking
a grid of
spatially distributed points along of each frame.
taking
a grid of
spatially distributed points along of each frame.
Thereafter,
the
scene flow, herein implemented, is computed among a couple
of frames to
obtain a basic 3D velocity representation of the sequence
for the cloud of
RGB-D points. In such way, each of the points ![]() gotten
from the dense
grid is tracked to the following frame from the respective
vector of
displacement
gotten
from the dense
grid is tracked to the following frame from the respective
vector of
displacement ![]() ,
computed in the scene
flow characterization. As in RGB strategies along
consecutive frames, the displacement
vector
,
computed in the scene
flow characterization. As in RGB strategies along
consecutive frames, the displacement
vector ![]() can
represent
incoherent abrupt motions. The displacement of the point is
filtered by using a
classical median operator, over a neighborhood
can
represent
incoherent abrupt motions. The displacement of the point is
filtered by using a
classical median operator, over a neighborhood ![]() ,
as,
,
as, ![]() ,
preserving the
structure of points along the sequence. The set of points
that are tracked
according to the associated velocity vector form the
,
preserving the
structure of points along the sequence. The set of points
that are tracked
according to the associated velocity vector form the ![]() motion
trajectory
motion
trajectory ![]() . A
typical trajectory
representation is illustrated in Fig. 2, where the
displacement of point
. A
typical trajectory
representation is illustrated in Fig. 2, where the
displacement of point ![]() is
drawn in blue, and
for the z-component, each trajectory is drawn using a
color-map, where green
represents trajectories that are close to the camera, while
blue represent low
motion in z. This 3D tracking introduces important features
about geometry of
the object as well as the 3D motion displacement developed
during a particular
action.
is
drawn in blue, and
for the z-component, each trajectory is drawn using a
color-map, where green
represents trajectories that are close to the camera, while
blue represent low
motion in z. This 3D tracking introduces important features
about geometry of
the object as well as the 3D motion displacement developed
during a particular
action.

Fig. 2. (3D+t) motion trajectories. In left subplot is illustrated the RGB-D information of captured hand. Then, between consecutive frames is computed a scene flow (middle subplot) that recovers the velocity of hand and hence its main geometrical structure. From such scene flow is tracked 3D points along video to obtain (3D+t) long trajectories as illustrated in right subplot. In this plot, color of trajectories represent the depth displacement, being green a color that represent that trajectories are close to the camera, while red color indicates that the trajectories are far. Please visit the site: (to be announced) to observe the image in color.
Source: The authors.
Some spatial filters are implemented to remove trajectories that have strong motions among consecutive frames or trajectories with static performance. These spatial filters are implemented by using the temporal thresholding of the trajectory’s variance. An illustration of the process to compute 3D motion trajectories is presented in Fig. 2, where left plot represent raw cloud point information, and, how scene flow is computed among consecutive frames (middle plot). 3D+t long trajectories (right panel) are then obtained by tracking several points from scene flow.
2.3 Kinematics trajectory features
The
set
of ![]() long
trajectories
captured along the video could be used as kinematic
independent words to
represent the gestures in a video. These trajectories are
rich in dynamic
spatio-temporal information and result fundamental to
characterize motion.
Then, a set of kinematic differential measures were computed
from each
trajectory to represent the words that represent a specific
activity. In this
work, it was computed the average
long
trajectories
captured along the video could be used as kinematic
independent words to
represent the gestures in a video. These trajectories are
rich in dynamic
spatio-temporal information and result fundamental to
characterize motion.
Then, a set of kinematic differential measures were computed
from each
trajectory to represent the words that represent a specific
activity. In this
work, it was computed the average ![]() and
standard deviation
and
standard deviation
![]() of
the local speed
along each trajectory, as:
of
the local speed
along each trajectory, as:![]() .
.
Since
trajectories
track motion points along the sequence and represent long
local
information, additional kinematics and analysis can be
carried out. For
instance, a complementary measure in this work was the
curvature, that allows
describing how rapidly the trajectory is bending along the
video. Also the
torsion was considered in this work as an additional 3D
measure of motion
trajectory. The computation of such metrics were implemented
according to [27],
following finite Euclidean differences. For instance the
curvature is
approximated by the circle that is circumscribed around
three consecutive
points of the trajectory ![]() .
Then, the curvature
.
Then, the curvature ![]() can
then be expressed
as:
can
then be expressed
as:
|
|
(4) |
where ![]() and
and
![]() ,
,
![]() and
and
![]() are
three consecutive
segments of the trajectory. Also, the torsion
are
three consecutive
segments of the trajectory. Also, the torsion ![]() could
be approximated
using six consecutive segments of the trajectory, as:
could
be approximated
using six consecutive segments of the trajectory, as:
|
|
(5) |
with
![]() as
the height of the
tetrahedron formed from each of the six consecutive segments
of the trajectory.
An important feature of the proposed
as
the height of the
tetrahedron formed from each of the six consecutive segments
of the trajectory.
An important feature of the proposed ![]() trajectories
is the
posibility to expand kinematics features that involve depth
information, as the
torsion.
trajectories
is the
posibility to expand kinematics features that involve depth
information, as the
torsion.
2.4 Mid-level trajectory representation for recognition
The set of computed motion trajectories constitutes a set of kinematics primitives to represent the particular performance of objects of interest. Each of the trajectories was codified with a set of kinematic measures as words of representation into Bag-of-kinematic words (BoKW). This mid-level representation is widely used in different areas of interest such as natural language processing,